Posted on
Making a website shouldn't be that difficult
Or so I thought.
I’ve just released my new portfolio at https://peach.smartart.it: this redesign started two years ago, with more or less 3 months non-stop of work during any spare time I had.
I’ve tried to put into it as many good practices and methodologies I could, only those that were fit for purpose and could help me ship something that would be extensible and as much future-proof as possible. Do you want to build your website too? Read through before you lose your mind.
After the release of my portfolio at https://peach.smartart.it, I've decided to analyse some of the main pain points I've gone through. In this article, I'll cover planning, workflow, and deployment: if you know how to deal with them, half of your work will be solved and you can concentrate on the actual work.
It’s all about planning
This website is about at its sixth iteration of design since 2004 and each one included some minor or major changes in the architecture, software, hardware or else.
What I’ve learned soon enough in my career as a developer and technical leader, is that
you need to plan as much as you can well in advance
because when things start to get heated and you’re getting close to delivery, most of the times you won’t have time to think, and you should be able to dedicate any additional effort at addressing the real unforeseen problems you will face later on.
This is the first and most important principle you have to digest.
I’ve had almost 5 different iterations to refine the product delivery path, going through UX, IA, UI, SEO and the overall Content Strategy. The basic concept to deal with this is using the classic divide and conquer paradigm, and break down the main specifications into smaller but still understandable bits of work.

The list I ended up having is quite extensive (for the size of the website I was building), but it helped me define what to design, how the content should have been organised, and any other type of in-between output I might have needed, such as wireframes and so on.
The usual workflow
Planning is just one of the most important bits, and together with it, we need to have an idea on how the workflow is managed. Or in other words:
How do you get from A to B with the least effort possible?
Going Agile is totally possible, but for a one-man job, it’s going to be a hell lot of overhead if you’re not used to it. Waterfall might be good enough, as long as we have all dependencies clearly visible in advance.
If I were to pick something, I would probably use Kanban for development purposes, and have a clear roadmap, with revisions of the backlog and the work done. I’ve already talked about Kanban before and there are some really good books and online articles on the topic if you want to dive a bit deeper into it. That’s quite easy, but once again, there’s no need for anything like that, unless you know what you’re doing: there are already too many in the industry picking up the latest fad and using it without knowing what they’re doing.
Understand the problem you’re trying to solve before choosing to go with anything.
And usually, you don’t know the problem you’re trying to solve, unless you’re already gone through the process yourself. So brace yourself if you haven’t, and I hope what I’m writing here can help you a bit more
Now, the problem I’m trying to solve is to track my progress, expose any unforeseen dependency, and highlight any possible obstacle (e.g. missing knowledge, configurations and setups, resolving a complex mathematical problem).
The best way to do that is by having a basic ticketing system associated with your code repository. BitBucket and GitHub provide two easy to use and free solutions you can start using straight away, but there are other that you can find with a simple online search.
With this I solve two main problems:
- Versioning my code
- Tracking my progress
Versioning is fundamental to be able to revert back, understand differences between changes, and see what’s in your production environment.
Tracking the progress will help you understand how much is left to be done and much you’ve accomplished. This might will also motivate you on the long run. With a project like this, when you have to invest a lot of your spare time can be quite stressful if you don’t know what’s left to do and what is needed to be done.
A ticketing system associated with my repository will allow me to manage the tickets using appropriately written commit messages. For example, by writing refs #ID or fixes #ID in the first line of my commit message, will associate automatically my commits to specific tickets and close them without any manual intervention.
Knowing how to write a decent and informative commit message is also important, regardless of what you’re trying to achieve; different companies and projects enforce their own structure, but you can start from this article about How to write a Git commit message.
Git is now the most used versioning system, and I quite frankly recommend it, unless you’re into weird stuff like Mercurial or Darcs (I know, they’re not weird, just lesser known).
So let’s recap: once you’ve done all your basic preparatory work, created tickets for each single task you need to accomplish, your repository will essentially dictate your workflow, and help you manage all the open tickets and deployment.
We will discuss the deployment process in the following section, but before we do, I’d like to give some more hints if you want to understand what to use as Git workflow: both BitBucket and GitHub provide some essential and well-written articles on it which I would recommend going through, and understanding it is extremely beneficial for your daily job as well if you’re a developer:
All systems are a GO
Now for the fun part, I’d like to highlight a couple of things that should be on the top of your list. Especially if you haven’t dealt with deployments in your daily job.
The basic problem to solve here is:
At whichever point I am with the development of my application, I should be able to release by just pressing a button.
This is not an easy one to solve because it involves some particularly delicate phases of your development cycle, such as:
- Hosting
- Hostnames and registrars
- Databases
- Deployment
- Testing
- Roll-back strategies
The list is a bit longer, but for our use-case scenario, this will suffice.
As for everything else, you want to lower the amount of effort involved into this. If you don’t require futuristic microservices, relational databases or anything that is not just serving pages via HTTP, you need to remove any additional requirement.
I don’t want to spend time managing a remote server, unless there’s a very important reason for that, e.g. core technology around which the whole system is based. I don’t want to spend time patching server flaws and upgrading software running on it, as it might be my own website. And if I do that, it should be the easiest thing to do. This is one of the many reasons why systems like Ansible have been created. And it’s also a reason why I started phasing out Drupal as my preferred CMS.
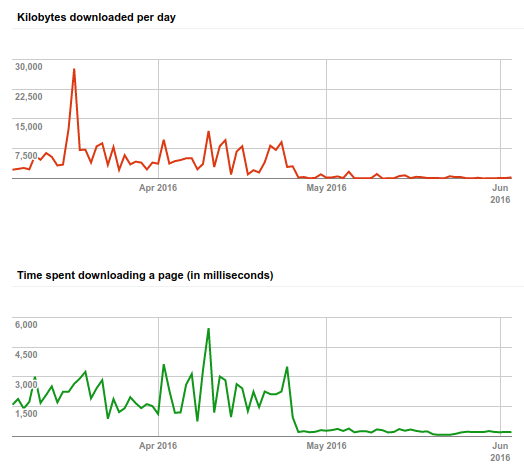
To keep things simple, I’ve decided to scrap off any database interaction, at least for the initial release. My website is now entirely static and I’ll be happy to talk about it in more detail in the future. I’ve also used a managed server hosting provider, although I could have used an Amazon S3 bucket, but since I was already paying for one, I’ve just used what I had.
Once I’ve decided where to host my files, the next question arises:
How do I develop and at the same time understand that my system is ready to be released?
In order to answer this question, I have to introduce the ability to separate different environments.
The minimal set of environments that I would look into is comprised of:
- A development environment, running on the local machine, for live coding;
- A pre-production environment, in an environment as close as possible to the production environment;
- The production environment. This is your live server where your main domain name is going to be pointed at.
There are many ways to solve #1, namely BrowserSync (or a similar technology) or using a Vagrant machine. The latter is usually the most flexible, but requires a lot of specific knowledge to start with as you can see in the article I wrote a while ago, the first is instead much more flexible and configuration-free.
The pre-production environment should be easy enough if your host is allowing you to have sub-domains.
Once you have the environments setup you have to look into how to prepare your files and send them over to your server.
With a static website as the one I had, having a dist or build folder where to place all the files as they would appear on the online server is probably the easiest solution: it will allow you to keep whichever folder structure outside of it and allow pre-processing any file without having to store them in your repository.
Although sending files might apparently seem to be extremely simple, I would like to stress that you need to have clean environments every time you go live in the pre-production or production environment. If your hosting provider gives you SSH access, I would suggest seeing if you have RSYNC available.
I now sync files using the following command line:
rsync -rlptDz --delete --progress -h source/ hostname:dest/
Rsync might not have the best manual in the world, but it might be your only way to understand how it works. Any other method is clearly perfectly fine.
At the end with this you should be pretty much solid for delivering your product without too many hiccups, leaving the heavy bits only to the development phase. Of course, there are a few other aspects you have to consider, but pretty much this solves it.
Some final notes
At this point, you can only go on and enjoy designing and coding your website. Most of my technical decisions ended up being driven by the actual requirements and the prioritisation I was doing on the features I wanted to have on the website.
I might not have explicitly said it but what I ended up having has been a progressively enhanced website: it provides basic accessibility and usability requirements, has got a solid enough foundation, separation of concerns between UI and logic, it's modular and scalable... Of course, my backlog is constantly increasing, prioritised, and refined, since only once you've released you will start gathering the needed analytics information to progress further and improve on the existing base.
I can further drill down in any of these topics, and in the meantime, I hope you've enjoyed the whole article.